

Simple repetition is learned in elementary programming classes. Repetition is implemented as a loop. There are three kinds of loops: top exit, middle exit, and bottom exit.
Top-exit loops:
while loop
for loop.
do ... until.
break or
return
The actual elapsed time (wall time) will depend on how long it takes the computer to get through all the repetitions of the loop.
Some times the wall time of the loop is important. Examples are when interacting with a human, or controlling a robot. In those cases, the loop body should not be repeated until the appropriate amount of time has elapsed. There are a few approaches to solving this problem of timed repetition.
while (test) { // simple repetition
stmt A
stmt B
}
while (test) { // adding for loop to delay repetition
stmt A
stmt B
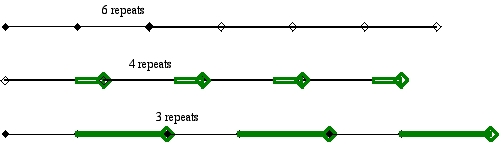
for (i = 0; i < MAX; i++) // loop to add time delay (green portion in picture)
;
}
MAX will delay the outer loop a short amount of time. If the added loop has
a large MAX, the outer loop will be delayed a longer amount of time.
The value of the upper limit can be determined during an initialization phase. You take a time stamp by accessing a system clock before entering a loop, iterate a fixed and known number of times, then take a time stamp after exiting. The ratio of the elapsed time to the number of iterations gives you the amount of time per single pass through. This ratio is than used to determined the desired number of iteration for a desired delay.
That kind of loop is called a busy-waiting loop. The CPU is kept busy doing wasted work. A busy-waiting loop is commonly used in very simple, low level applications for input (or output) control. An input device will set a bit in a control/status register when input has been received at the device. The CPU executes a busy-wait loop, fetching the control/status register then testing the value of the "input ready" bit. If the bit is not set, then continue the busy-wait loop. If the bit is set, then exit the loop and then read the input from the input device's data register into the CPU.
The problem with using a busy-wait to make a timed loop is a lack of accuracy and repeatability. The loop is not repeating every k milliseconds; it is repeating every k +/- ε milliseconds, where ε is a varying amount of error. It is the busy-wait code that has the more repeatable and more accurate elapsed time; the productive code may have different execution times depending on different paths taken through the executable.
delay()
(or sleep()) function, then the delay() function call can be placed
in the body of the timed loop. The delay() function will take a parameter that specifies
how long the currently executing task is put to sleep. The operating system will manage the task
state change for the task: when the task executes the delay(), the operating system
(that manages task state transition) will change the task's state
from RUNNING to BLOCKED. After the indicated time has elapsed, the operating
system will change the task's state from BLOCKED to READY. At the next
opportunity, the OS will change the task's state from READY to RUNNING.
The task "wakes up" (generally a timer will go off and code (in the part of the OS
called the Scheduler) will assign the CPU to the task and change the task's state
to RUNNING); the task resumes execution at the
next statement after the delay(). The task
will not realize it has been asleep.
In terms of the accuracy of the timed loop, busy-waiting and a delay()
are equally inaccurate. The advantage of delay() is that the operating system
can use the time one task is asleep to give the CPU to a different task that can do
productive work. On the other hand, busy-wait is most frequently used in a situation where there is
no multi-tasking for very low-level data transfer; the busy loop, rather than just
wasting time repeatedly checks a bit to see if new data is ready to be transferred.

For the reasons given above, code that is invoked at regular intervals is better, in terms of accuracy and efficient use of the CPU, than putting the code in a loop that needs timing control.